需要重写equals()方法的类,也需要重写hashcode(),不然在使用HashMap或者HashSet类时,会出现不正确的结果。
那么什么时候需要equals()方法呢?
Object类的equals()实现为比较对象的引用地址,所以,不想比较对象引用,而比较其他情况时,需要重写equals()方法。
大多情况下,我们需要比较对象的变量是否相等,此时,这种类型被称为“值类型”。
对于枚举类型,如果我们需要比较其变量相等情况时,看看是否需要重写equals()和hashcode()?
语法糖
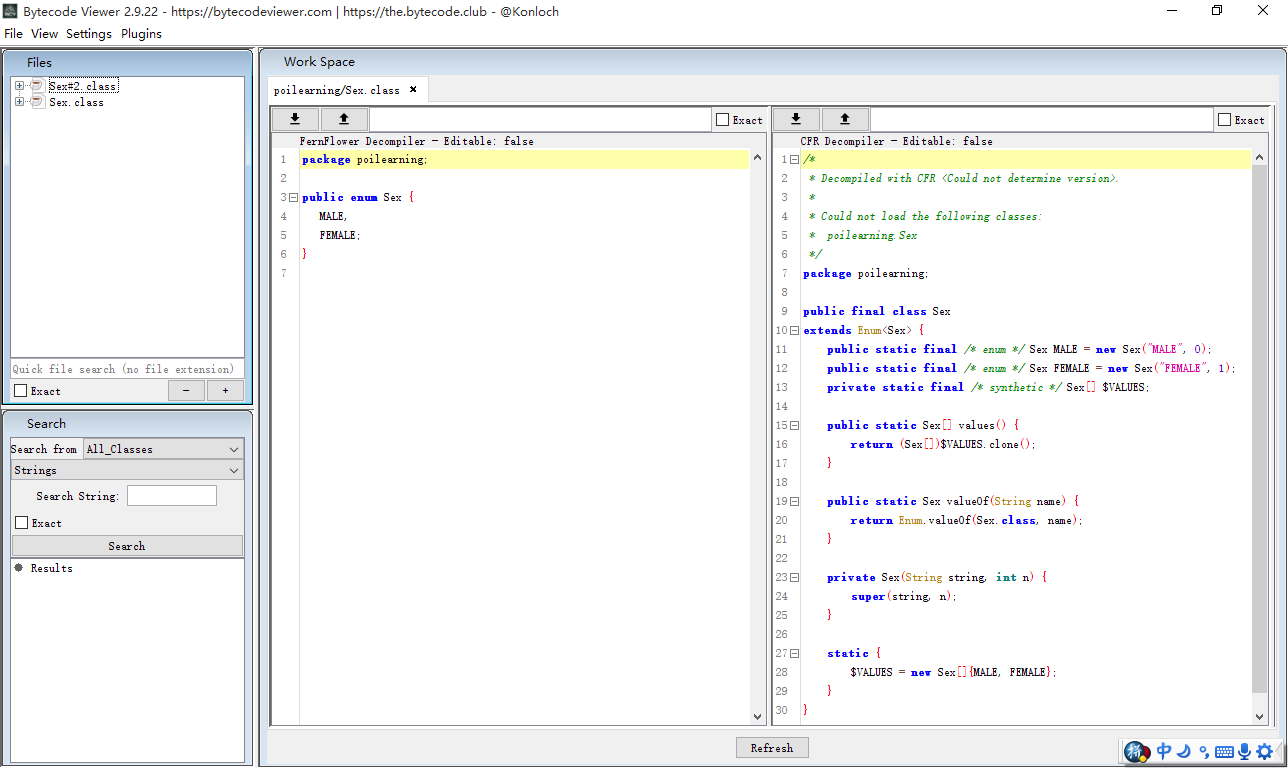
枚举类型enum为Java语言的一个语法糖,可以使用反编译工具,看一下Java编译器是否如何实现enum的。
源代码:
1 | enum Sex{ |
反编译的代码:
1 | static final class JavaSugar.Sex |
通过反编译后的代码,我们可以看到:
- 构造函数为私有的,所有的枚举值都是静态创建。这属于懒汉式的单例模式,并且创建过程是线程安全的。
- 类型和所有的枚举值都由final来修饰,并且所有方法对于变量操作都是只读的。说明这是一个不可变类型。
枚举同时具备单例模式和不可变类型,这样整个Java应用中的枚举类型实例就只有定义的枚举值(MALE和FAMALE)。
这样,不同枚举值的变量(name)理论上是不会出现相等情况的(除非定义枚举值使用相同的变量值,但这个枚举的意义是相悖的)。引用不同的枚举对象,其枚举变量肯定是不同的。
所以,结果是: 枚举类型不需要重写equals()方法和hashcode()方法。
枚举类型的反序列化
枚举类型是否还有其他方式创建枚举值?我不能确定反序列化是否有新的方式来创建枚举值。
通过阅读反序列化的源代码,可以窥探一二。
默认情况下,序列化枚举实例,得到的结果为枚举的name变量值。
Enum类,提供了valueOf(Class<T> enumType,String name)方法,可以使用name值得到枚举实例。
其源代码:
1 | public static <T extends Enum<T>> T valueOf(Class<T> enumType, |
再看一下enumConstantDirectory()方法:
- enumConstantDirectory为一个
name->Enum Type的Map1
2
3
4
5
6
7
8
9
10
11
12
13
14Map<String, T> enumConstantDirectory() {
if (enumConstantDirectory == null) {
T[] universe = getEnumConstantsShared();
if (universe == null)
throw new IllegalArgumentException(
getName() + " is not an enum type");
Map<String, T> m = new HashMap<>(2 * universe.length);
for (T constant : universe)
m.put(((Enum<?>)constant).name(), constant);
enumConstantDirectory = m;
}
return enumConstantDirectory;
}
private volatile transient Map<String, T> enumConstantDirectory = null;
再看一下getEnumConstantsShared()方法:
1 | T[] getEnumConstantsShared() { |
上述getMethod("values")方法,应该就是下面的方法。这样的话,valueOf(Class<T> enumType,String name)方法返回的枚举实例,并没有创建新的实例。
1 | public static JavaSugar.Sex[] values() { |
反序列化,有很多方式,这里看一下ObjectInputStream和Gson两种方式:
ObjectInputStream
其核心代码如下:
1 | private Enum<?> readEnum(boolean unshared) throws IOException { |
其创建实例的代码:
1 |
|
所以,其不会创建新的枚举实例。
Gson
核心代码如下:
1 | private static final class EnumTypeAdapter<T extends Enum<T>> extends TypeAdapter<T> { |
classOfT.getEnumConstants()方法的源代码如下
1 | public T[] getEnumConstants() { |
这个getEnumConstantsShared()方法,我们上面已经看过了。
这样,Gson反序列化,也不会产生新的实例。
总结
反序列化,并不会创建新的枚举实例。